Understand and explore the power of scientific programming
Giant Number Crunching: Decoding a 2 Trillion Operation Matrix Benchmark
"What happens when you subject native C and Julia to a massive, 2-trillion-operation stress test? In this benchmark, we look beyond the 'language wars' to reveal how underlying memory layouts—Row-Major vs. Column-Major—can fundamentally dictate the performance of your physical CPU "
PROGRAMMING
Rahul Mahajan
5/26/20264 min read
Introduction
In high‑performance computing, C has long been considered as heavy weight champion in terms of raw speed. But when Julia goes head‑to‑head with native C in a heavy numerical drag race, the results are interesting. In addition to choice of language, performance depends on memory layout.
The Benchmark Battlefield
To challenge raw processing power, we designed a dense matrix multiplication experiment:
Workload: (10,000 ×10,000) floating‑point matrix multiplication.
Operations: 2 trillion individual calculations (2 ×m ×n ×k)
Hardware: AMD Ryzen 3 3200U (2 cores, 4 threads, 2.60–3.50 GHz boost) with 8 GB RAM
Backend: OpenBLAS, targeted identically by both C and Julia
Timing: High‑resolution hardware timers (QueryPerformanceCounter for C, @benchmark for Julia)
Theoretical Peak Performance
With above mentioned CPU, each core can execute 8 double‑precision FLOPS per cycle at 3.50 GHz boost
2 Cores × 3.5GHz × 8 FLOPS per cycle. = 56.0 GFLOPS (Giga Floating Point Operations Per Second)
This sets the ceiling for achievable performance.
Setup for Experiment
C Project Download from here and extract the files to your working directory
To achieve a true hardware-level benchmark without performance bottlenecks, the C code is split into a modular structure.
In working directory, you will find following files.
1. c_include.h — The Project Blueprint
This header file acts as the central hub for the entire application.
Global Configuration: It gathers all the necessary standard libraries (like <stdio.h> and <stdlib.h>) and links your local installation of the OpenBLAS library (cblas.h).
The Matrix Structure: It defines a custom data structure called Array. This structure wraps a flat, dynamic pointer (*data) along with its row (r) and column (c) dimensions, transforming raw memory blocks into manageable objects.
2. io_ref.h & io_ref.c — The File & Memory Manager
This module handles the heavy lifting of reading files from your disk and keeping your system memory clean.
Csv_Read: This function safely allocates a block of Dynamic Memory (DMA) on the heap to store your matrices. It opens your data files (Matrix_A.csv, Matrix_B.csv) and parses them token-by-token using fscanf, verifying that the file is not empty or corrupted before passing it to the math engine.
Csv_Write & C_Print: Utility functions built to output your matrix results smoothly, either back to a comma-separated disk file or straight to your terminal screen.
C_Release: An advanced cleanup function. It uses C's variadic arguments feature (stdarg.h), allowing it to accept multiple matrix variables at once (e.g., C_Release(3, &A, &B, &C)) to instantly free up your system RAM and prevent memory leaks.
3. DGEMM.c — The Execution Core
This is the main entry point where the actual magic happens.
Threading Control: Before performing any math, it calls openblas_set_num_threads(4). This explicitly locks the calculation to 4 threads, ensuring OpenBLAS utilizes AMD Ryzen processor symmetrically.
The Win32 Hardware Stopwatch: It implements GetRealWorldTime(), which queries the Windows kernel directly using QueryPerformanceCounter. By capturing the exact counter ticks right before and right after the calculation, it measures pure real-world passage of time down to the microsecond.
cblas_dgemm: The grand finale. It calls the raw OpenBLAS assembly kernel to execute the matrix multiplication in strict Row-Major order. Because it passes through a flat memory layout.
Julia Project The Julia code is comparatively cleaner and smaller. The code snippet given below can be used as it is.
Python Matrix Generator
With the python, you can generate N x N matrix easily
Implementation of OpenBLAS
The C project uses OpenBLAS under the hood. So you must download the same from here
Further if you dont know how to link and compile the OpenBLAS with C, then you can refer to compile instructions
Run the C code
Navigate to your working directory where you extracted your project files. With shift button pressed, press right click. (It will open command prompt right there) and enter following command ( I assume you have MinGW compiler installed in your system.)
The moment, calculation starts, the CPU starts heavy lifting. The screenshot depicts this performance blast of processor.
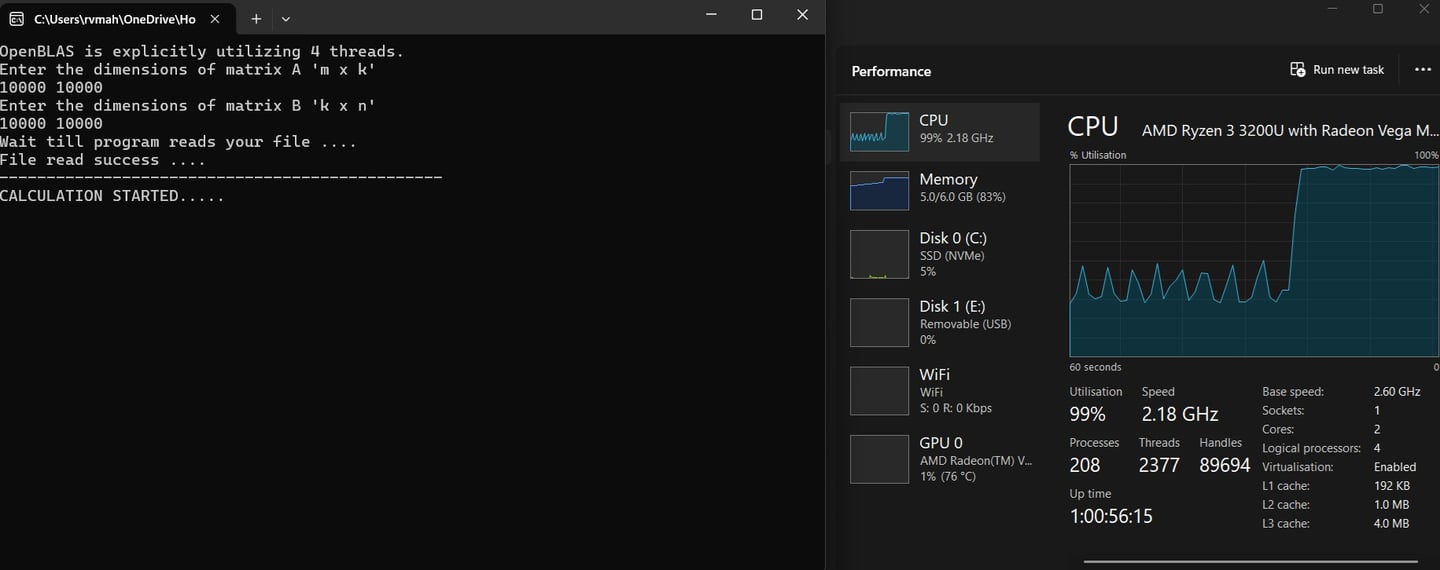
Run the Julia code
Run the following script in Julia terminal using
include("path_to_your_filename.jl") replace path_to_your_filename with actual path.
make sure you keep the files Matrix_A.csv and Matrix_B.csv in same folder as that of your julia script ".jl file"
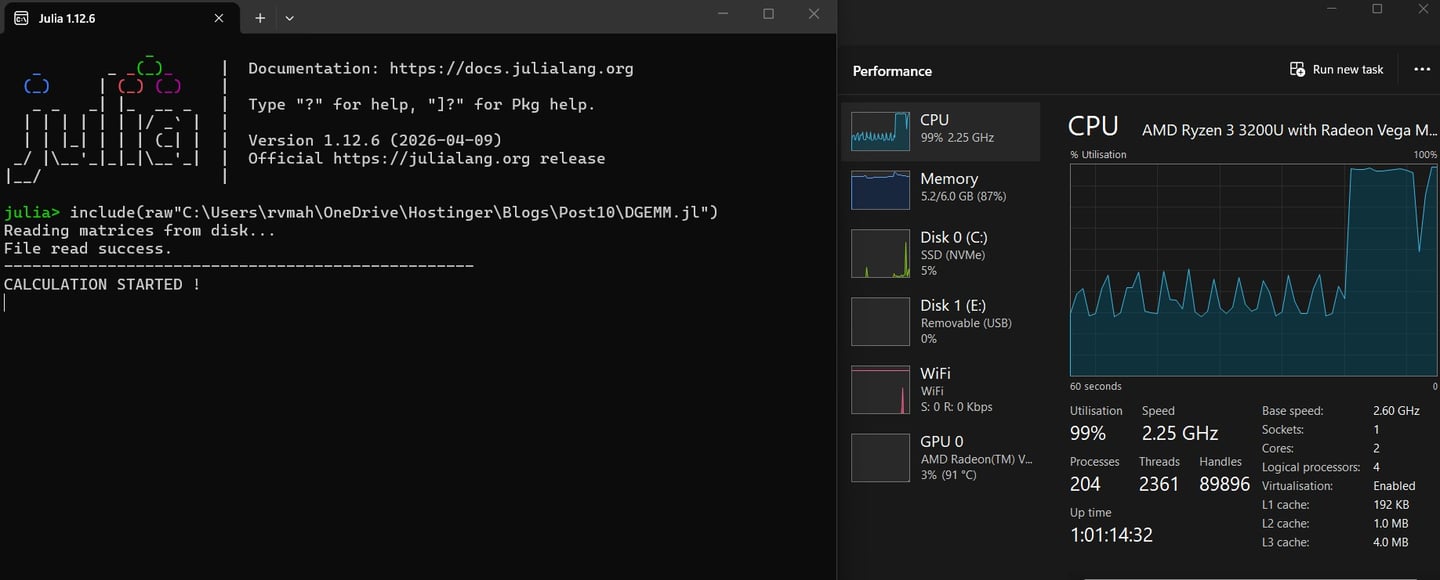
Results: Stopwatch Reality

Understanding Efficiency numbers:
Why Memory Layout Wins – The secret to surprise
1. C and the Row‑Major Obstacle
C stores matrices row‑by‑row. BLAS kernels, optimized for Fortran‑style column access, must jump across non‑contiguous memory. This causes cache misses and pipeline stalls.
2. Julia and the Column‑Major Advantage
Julia stores matrices column‑by‑column. Data streams align perfectly with BLAS expectations, allowing the CPU’s pre‑fetcher to keep caches full. The processor avoids stalls and sustains boost clocks longer, shaving seconds off execution.
In short two workers C and Julia were given identical job. Only difference was the environment to which worker Julia was subjected was slightly more ergonomic.
Final Thought
Achieving nearly 45-48% of theoretical peak performance on a 15‑watt mobile processor is not bad. More importantly, the experiment shows that true speed isn’t just about choosing a “fast” language—it’s about matching data structures with hardware being utilized.
As a modern software engineers, this lesson certainly is far beyond matrix mathematics: whether it is machine learning, databases, or GPU programming, performance lies at the intersection of data layout and hardware under operation.
Leave a reply
scientificprogramming.in
Explore scientific programming
Contact author
© 2025. All rights reserved.